yasmeenzeena.github.io
Human Genome
This can be split up into the nuclear genome and the mitochondrial genome. Mitochondrial genome is inherited purely from the maternal line and there is no recombination. Of the 37 genes it encodes 22 are tRNA genes, 13 are for enzymes involved in oxidative phosphorylation (main role of mitochondria = OxPhos) and 2 make rRNA. Mitochondrial genomes are small but there are many mitochondrial per cell, so their genome can account for up to 0.5% of the cell’s DNA!
- nuclear genome = 25,000 genes; mitochondrial genome = 37 genes; 22 tRNA, 2 rRNA, 13 for enzymes in OxPhos. </br>
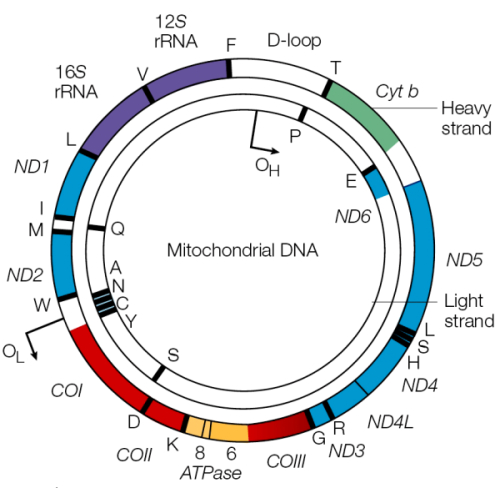
Structure of the Mitochondrial Genome
Circular! Double stranded: one heavy & one light strand. Heavy is G-rich so has more double ring structures (purines), light is C rich so has more single ring structures (pyrimidines.)
Neither strand has any overlapping genes! There are also no introns (bacterial descendant.) No introns => whole strand is transcribed as one unit and then cleaved into individual mRNAs. No need for multiple promoters but all genes are expressed together.
Heavy: 28 genes encoded, G rich, purines Light: 9 genes encoded, C rich, pyrimidine

a tiny section of the mitochondria DNA forms a “D loop”, where it actually is triple stranded DNA. A section of complimentary DNA comes in and replaces the heavy strand and hydrogen bonds to the light strand for a little while. Replication of the mitochondrial DNA starts in either direction at the D loop. Large parts are highly variable and the region has proven to be useful for the study of the evolutionary history of vertebrates
Nuclear Genome Structure
Chromosomes are numbered by size (1 is the largest etc.) They have a “p” strand (petite) and a “q” strand (the longer one.) 23 chromosomes are made from 22 autosomes (i.e. somatic) and one sex chromosome.
Only 1.5% of the genome codes for human proteins! LINES&SINES take up anywhere from 30% to almost 50%, and introns another 30%. Thus duplications and repeats account for most of the genome.
Gene Regulation
DNA is arranged intron->exon->intron->exon. Before and after the exon (i.e. the gene) is a flanking region. The 5” flanking region contains the promoter (binds RNA polymerase) and the enhancer®ulatory sequences if applicable (binds additional proteins to stabilise RNA polymerase complex.) It is not transcribed nor translated.
The introns are spliced out of mRNA by spliceosome complexes during posttranscription and a polyA tail is added (exons are re-ligated.) A methyl cap is added to the polyA tail. This process is called “splicing” in eukaryotes.

Proteins with much larger gene sizes have a higher risk of mutation as it takes longer for the transcription/translation machinery to work. E.g. the longest human gene is 2600kb, Dystrophin (16h to transcribe.) Duchenne muscular dystrophy occurs when mistakes are made in this gene.
About 10% of the genome codes for RNAs rather than proteins: mRNa, rRNA, tRNA, microRNA (regulation roles), sn and snoRNA (small nuclear & small nucleolar.)
Gene Families
Gene duplication and subsequent mutation of the duplicates can result in the formation of a “gene family.” E.g. haemoglobin genes: genes for the alpha globular protein subunits sit on chromosome 16 and there are three types, coding for embryo, fetus and adult versions (so 3 duplicates were made and mutated.) genes for the beta globular protein subunits occur on chromosome 11, and also feature embryo, fetus and adult versions. Genes are arranged in developmental order, although we are unsure why. Duplication = change to optimise each duplicate for different life stages through mutation (evolution)!
e.g. Histone gene family: H1, H2A, H2B, H3 & H4. Histones are proteins around which DNA is wrapped during replication. The DNA-histone complex = “nucleosome”. This ensures fast and correct DNA packaging. Histone genes are arranged into 11 clusters with over 60 actual genes distributed over 7 chromosomes. Each histone gene encodes an identical protein -> there are 60 because they are needed quickly and in great numbers in DNA replication, so multiple copies = multiple proteins made at once. Histone genes have no introns which removes the need for splicing, speeding up the process.
Gene families can be arranged:
- on different chromosomes (histones)
- on the same chromosome (haemoglobin subunits)
Pseudogenes
Gene sequences which cannot code for protein: non-processed pseudogenes are genes that acquired mutations over time becoming non-functional. Processed pseudogenes are genes that have lost their function after being moved around the genome by retrotransposition. Processed pseudogenes can also arise via cell invasion of reverse transcriptase: some DNA sequences have been observed to have polyA tails and a lack of introns, suggesting that they arose from mRNA which reverse transcriptase had turned back into DNA and reinserted into the chromosome (i.e. transposons that copy and paste their genetic information rather than cut and paste it.) There are not transcribed into mRNA as their promoter is missing. Processed pseudogenes are usually found on a different chromosome to their functional gene counterpart.
- non processed = arose by duplication and mutation of the gene
- processed = retrotransposon / reverse transcriptase copy & pasted
Transposon
DNA sequence with ability to move around in the genome = “jumping genes” an independent entity residing within the genome, encodes all the enzyme needed for its own transposition = selfish element. Transposons are sometimes viewed as selfish DNA, which is defined as sequences that propagate themselves within a genome without contributing to the development and functioning of the organism.
Most of the transposons in the human genome are nonfunctional; very few are currently active. One interesting feature is that some currently functional genes originated as transposons and evolved into their present condition after losing the ability to transpose. At least 50 genes appear to have originated in this manner.
TEs effectively act as intracellular parasites and, like other parasites, may need to strike an evolutionary balance between their own proliferation and the detrimental effects on the “host” organism…Transposons are restricted to moving themselves, and sometimes additional sequences, to new sites elsewhere within the same genome.
Transposons are responsible for the high level of repetition within human DNA (almost 50% of the genome is repeats) as their mechanism relies on copy pasting themselves, i.e. a section of DNA, back into the genome many times.
-
Class I = retrotranspons, code for reverse transcriptase; DNA -> RNA -> back to DNA, which is inserted at a different point in the genome. The reverse transcriptase used is often coded for by the transposon gene itself. Confined to eukaryotes. [Recent phylogenetic evidence suggests that retroviruses as a class are simply retrotransposons that have acquired envelope proteins, the inverse of the previously assumed relationship.] -> can think of retrotransposons as “intracellular virus” but not a virus bc lacks protein coat. The promoter is transcribed with the rest of the genes to allow the inserted retrotransposon to continue to proliferate.
-
Class II = DNA transposons, do not code for reverse transcriptase; use transposase enzymes to cut out the DNA from the genome -> enzymes can bind site specifically or generally, and produce sticky ends. DNA polymerase fills in the gaps created by the sticky ends and DNA ligase fixes the backbone. The transposon in question will encode the enzymes required for its own transposition, but will require cell machinery.
{kind=link}
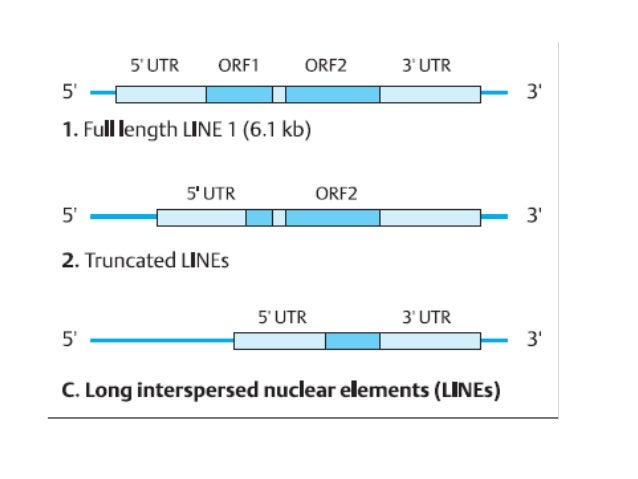
LINES: L1, “long interspersed nuclear elements”
20% of the genome; 900,000 copies.
Class I i.e. they code for reverse trascriptase and insert themselves into the genome via an mRNA intermediate. They have a promotor and two separate open reading frames to code for the reverse transcriptase, the endonuclease & the RNase H. LINES are defined by “target site duplication” sequences on either side of their genetic information. As they are mRNA integrations into DNA they have a polyA tail at the 3’ end.
- Target site duplication at either end
- A promoter for transcription
- ORF1 = Reverse transcriptase to copy the RNA to DNA
- ORF2 = Endonuclease to cleave the target DNA e.g. RNase H (ribonuclease H) for RNA removal
- 5’ UTR contains the promotor, 3’ UTR has the poly A tail
- untranslated region = sequences which are transcribed but not translated
LIFE CYCLE OF LINES:
- LINE DNA is transcribed and translated via host cell machinery (not the UTR or the TSD) –>
- ORF1 and ORF2 proteins (reverse trascriptase, endonuclease, RNase H) bind to the LINE mRNA (i.e. proteins, the translation product, bind to mRNA, the transcription product)(LINE mRNA is not destroyed during translation) —>
- Protein-mRNA strand is moved back into the nucleus (proteins escort the mRNA)
- this LINE mRNA complex can anneal to sequences of DNA with a TTTT rich region (binds to poly A tail) (AT rich regions are weaker)–>
- LINE endonuclease cleaves the dsDNA at the target site (“target site cleavage”) —>
- Insertion of the LINE —>
- RNA DNA hybrid forms —>
- LINE RNA uses the DNA strand it’s bonded to as a template, begins to synthesis the first cDNA strand using reverse transcriptase (LINE mRNA -> LINE DNA) –>
- Four bp(+) on the end of the LINE is removed as they do not match to the DNA —>
- DNA repair fills in the missing sequence, formation of TSD (transcription site duplication) —>
- DNA ligase joins up the new DNA strands, LINE has been successfully inserted
LINE in DNA is copied into both proteins and mRNA; they react together to form a complex which can break into complimentary DNA and insert itself into the genome, where the mRNA is copied into dsDNA.
A LINE is about 6500bp, but is often truncated at the 5’ end -> i.e. reverse transcriptase misses a bit of the 5’ end when turning the mRNA into DNA to be inserted into the cell. The promoter is often missing, which means that this inserted LINE cannot be transcribed again so no more duplication of the LINE = processed pseudogene.
LINES are mutagens and their movements are often the causes of genetic disease. They can damage the genome of their host cell in different ways:
- inserts itself into a functional gene, most likely disables that gene; (causes frameshift mutation/ inversion, deletion)
- after a DNA transposon (Class II, no reverse transcriptase) leaves a gene, the resulting gap will probably not be repaired correctly;
- transposons result in areas of the DNA being complimentary (many repeats across many chromosomes), called “portable regions of homology” -> these may accidentally recombine rather than with their chromosome counterpart. Such exchanges result in deletions, insertions, inversions, or translocations.
- altered gene expression if inserted into regulatory regions, e.g. ⋅⋅⋅ insertion into promoter can silence a gene -> X-linked muscular dystrophy, Haemophilia A and B, colon cancer .. ⋅⋅⋅ LINE insertion in the FMO1 gene in human liver cells stops its expression .. ⋅⋅⋅ insertion into intron can slow down transcription ..
- multiple copies of the same sequence, such as Alu sequences, can hinder precise chromosomal pairing during mitosis and meiosis, resulting in unequal crossovers, one of the main reasons for chromosome duplication.
LINES = 0.2% of all genetic diseases, uncommon in somatic cells (most damage is done during homologous recombination in meiosis in germ line cells.) Somatic cells heavily methylate many large swaths of genes and so the LINES are “silenced” and cannot transcribe themselves.
SINES
“short interspersed elements” -> e.g. Alu sequence, the most abundant repeat in the genome (750,000 times.) Only occurs in the intron sequence, not in any exons. 280-300bp long roughly & primate specific! Alu regions can be detected by digesting DNA with restriction endonuclease Alu 1 (cuts out the Alu sequence, can be visualised on a gel: lots of Alu repeats —> not a smear but just many sequences on top of one another showing that this is a reoccuring sequence (v abundant in comparison to rest of genome.)
Alu repeat structure:
- TSD at the beginning (target site duplication, the inverted repeat that signals a transposon beginning and end)
- Transcription start site
- Binding site A and B (RNA polymerase binds here, A&B are essentially promoters)
- poly A tail and complimentary T section on other strand
- TSD at the end
SINEs all have RNA pol III internal promoters (A&B in Alu.) SINES are transcribed by RNA polymerase III, then the SINE mRNA is copied into DNA via reverse transcriptase -> this is donated by a LINE element. SINES cannot make their own reverse transcriptase as they do not encode the gene for it! Insertion of SINES are thought to be involved in the formation of Haemophilia A and B, chronic haemolytic anaemia and cystic fibrosis.